Introducing mcpx-eval: An open-ended tool use evaluation framework

Looking for secure MCP controls to connect AI and your work apps? Check out Turbo MCP, our self-hosted enterprise tool management solution: https://dylibso.ai/#products
The AI landscape is evolving rapidly, and with almost daily advancements, it can be hard to understand which large language model (LLM) makes the most sense for the task at hand. To make things more complicated, each new model release comes with new claims regarding capabilities that don't necessarily translate to all workloads. In some cases, it will make sense to stick with an older model to save on time or cost, but for others, you might need the cutting-edge reasoning abilities of a newer model. The only way to really understand how an LLM will perform a specific task is to try it out (usually a bunch of times). This is why we're happy to announce mcpx-eval, our new eval framework to compare how different models perform with mcp.run tools!
The Berkeley Function Calling Leaderboard (BFCL) is the state-of-the-art for measuring how well various models perform specific tool calls. BFCL includes many specific tools created for particular tests being performed, which allows for tool use to be tracked closely. While this is extremely valuable and we may still try to get mcp.run tools working in BFCL, we decided it would be worth building an mcp.run-focused eval that could be used by us and our customers to compare the results of open-ended tasks.
This means instead of looking at very specific outcomes around tool use, we're primarily interested in trying to quantify the LLM output to determine how well they perform in situations like Tasks, where many tools can be combined to create varied results. To do this, we're using a custom set of LLM-based metrics that are scored by a secondary "judge" LLM. Using static reference-based metrics can provide more deterministic testing of prompts but are less helpful when it comes to interpreting the "appropriateness" of a tool call or the "completeness" of a response.
To peek behind the curtain a little, we can see how the judge prompt is structured:
<settings>
Max tool calls: {max_tool_calls}
Current date and time: {datetime.now().isoformat()}
</settings>
<prompt>{prompt}</prompt>
<output>{output}</output>
<check>{check}</check>
<expected-tools>{', '.join(expected_tools)}</expected-tools>
There are several sections present: <settings>, <prompt>, <output>,
<check> and <expected-tools>
settingsprovides additional context for an evaluationpromptcontains the original test prompt so the judge can assess the completeness of the outputoutputcontains all the messages from the test prompt, including any tools that were usedcheckcontains user-provided criteria that can be used to judge the outputexpected-toolsis a list of tools that can be expected to be used for the given prompt
Using this template, the output of each LLM under test along with the check criteria is converted into a new prompt and analyzed by the judge for various metrics which we are able to extract into structured scoring data using PydanticAI. The result of the judge is a Python object with fields that hold the numeric scores, allowing us to analyze the data using a typical data processing library like Pandas.
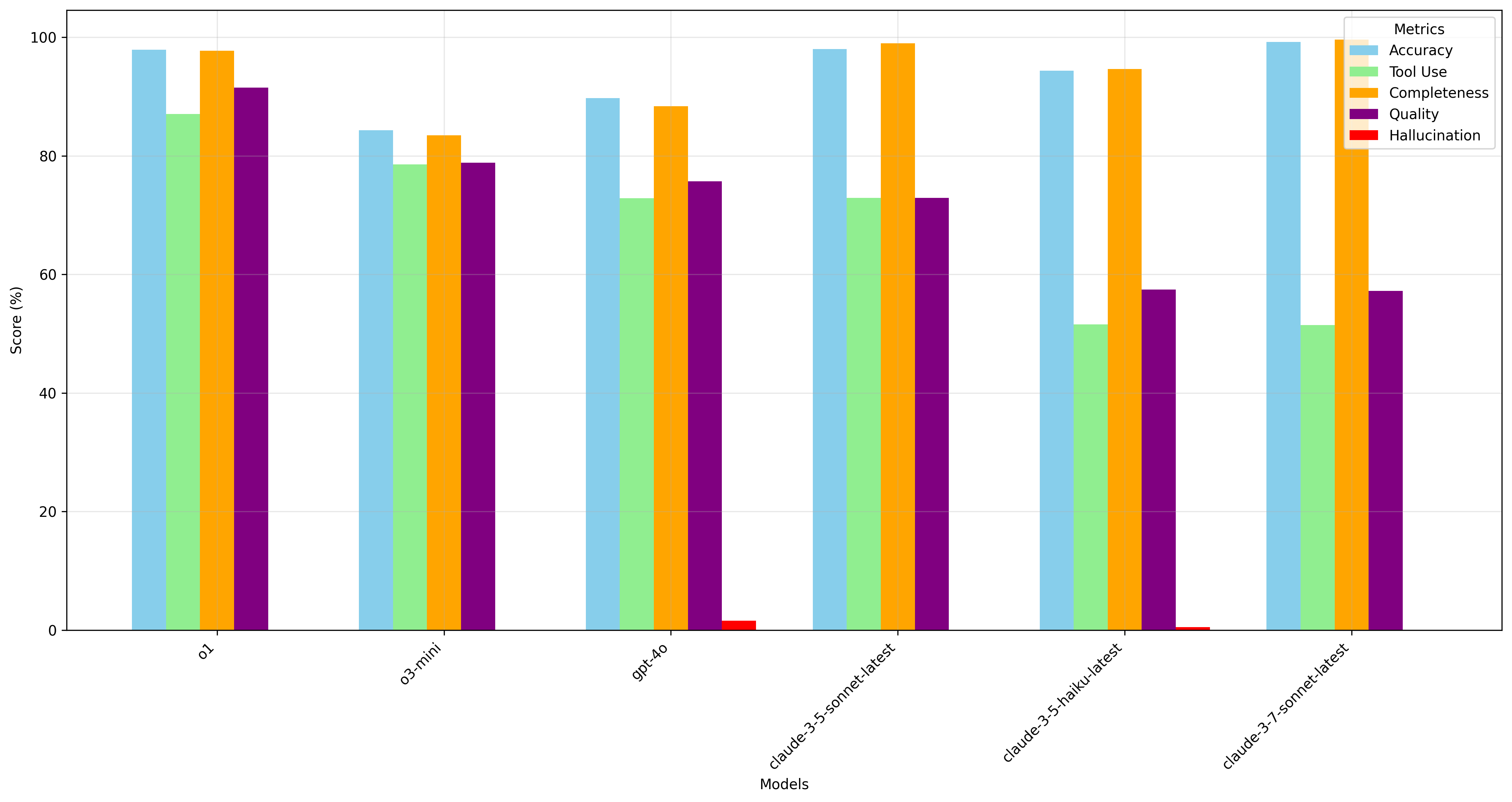
This is just scratching the surface - our preliminary results already reveal interesting patterns in how different models handle complex tool use scenarios. For example, one of the biggest problems we're seeing is over-use, which doesn't affect the quality of the output but does affect compute time and cost. These measurements can help us provide the information to give teams more confidence when selecting models for use with mcp.run tools.
Looking forward, we're planning to expand our test suite to include more models and cover more domains. Please reach out if you have a specific use case you'd like to see evaluated or are wondering how a particular model performs for your task. The mcpx-eval code is also available on Github.